from textplumber.textstats import TextstatsTransformer
from textplumber.preprocess import SpacyPreprocessor
from textplumber.store import TextFeatureStore
from textplumber.core import get_example_data
from textplumber.report import plot_confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import RFECVtextstats
Extract document-level statistics as features.
TextstatsTransformer
TextstatsTransformer (feature_store:textplumber.store.TextFeatureStore, columns:list=['tokens_count', 'sentences_count', 'characters_count', 'monosyllabic_words_relfreq', 'polysyllabic_words_relfreq', 'unique_tokens_relfreq', 'average_characters_per_token', 'average_tokens_per_sentence', 'characters_proportion_letters', 'characters_proportion_uppercase', 'hapax_legomena_count', 'hapax_legomena_to_unique'])
Sci-kit Learn pipeline component to extract document-level text statistics based on the textstat library and pre-computed counts. This component should be used after the SpacyPreprocessor component with the same feature store.
| Type | Default | Details | |
|---|---|---|---|
| feature_store | TextFeatureStore | the feature store to use | |
| columns | list | [‘tokens_count’, ‘sentences_count’, ‘characters_count’, ‘monosyllabic_words_relfreq’, ‘polysyllabic_words_relfreq’, ‘unique_tokens_relfreq’, ‘average_characters_per_token’, ‘average_tokens_per_sentence’, ‘characters_proportion_letters’, ‘characters_proportion_uppercase’, ‘hapax_legomena_count’, ‘hapax_legomena_to_unique’] | the textstats to use |
TextstatsTransformer.fit
TextstatsTransformer.fit (X, y=None)
Fit is implemented but does nothing.
TextstatsTransformer.transform
TextstatsTransformer.transform (X)
Transforms the texts to a matrix of text statistics.
TextstatsTransformer.get_feature_names_out
TextstatsTransformer.get_feature_names_out (input_features=None)
Get the feature names out from the text statistics.
Available statistics for each text
The following document-level statistics are extracted by SpacyPreprocessor and are available as potential features for each text …
- tokens_count: The total count of word and punctuation tokens.
- sentences_count: The count of sentences.
- characters_count: The count of non-space characters.
- monosyllabic_words_relfreq: The ratio of mono-syllabic words to all tokens.
- polysyllabic_words_relfreq: The ratio of poly-syllabic words (i.e. words with three or more syllables) to all tokens.
- unique_tokens_relfreq: The ratio of unique tokens to all tokens. This is equivalent to Type-Token Ratio (TTR). Tokens are lower-cased to extract unique tokens (i.e. ‘Word’ and ‘word’ are equivalent).
- average_characters_per_token: The ratio of characters_count to tokens_count.
- average_tokens_per_sentence: The ratio of tokens_count to sentences_count.
- characters_proportion_letters: The proportion of all non-space characters that are letters.
- characters_proportion_uppercase: The proportion of all non-space characters that are uppercase letters.
- hapax_legomena_count: A count of words used only once in a text.
- hapax_legomena_to_unique: The proportion of unique tokens that are only used once in the text.
Example
Here is an example …
Here we load text samples from Ernest Hemingway and Virginia Woolf available in the AuthorMix dataset.
X_train, y_train, X_test, y_test, target_classes, target_names = get_example_data(label_column = 'style', target_labels = ['hemingway', 'woolf'])Setup a feature store for this classification task …
feature_store = TextFeatureStore('feature_store_example_textstats.sqlite')Specific document-level statistics can be used as features for text classification. For example, can we predict the author from the following document-level statistics?
- polysyllabic_words_relfreq
- unique_tokens_relfreq
- average_tokens_per_sentence
- hapax_legomena_to_unique
pipeline = Pipeline([
('preprocessor', SpacyPreprocessor(feature_store=feature_store)),
('textstats', TextstatsTransformer(feature_store=feature_store,
columns = ['polysyllabic_words_relfreq',
'unique_tokens_relfreq',
'average_tokens_per_sentence',
'hapax_legomena_to_unique'])),
('scaler', StandardScaler(with_mean=False)),
('classifier', LogisticRegression(max_iter = 5000, random_state=55))
], verbose=True)
display(pipeline)Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('textstats',
TextstatsTransformer(columns=['polysyllabic_words_relfreq',
'unique_tokens_relfreq',
'average_tokens_per_sentence',
'hapax_legomena_to_unique'],
feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('textstats',
TextstatsTransformer(columns=['polysyllabic_words_relfreq',
'unique_tokens_relfreq',
'average_tokens_per_sentence',
'hapax_legomena_to_unique'],
feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)
TextstatsTransformer(columns=['polysyllabic_words_relfreq',
'unique_tokens_relfreq',
'average_tokens_per_sentence',
'hapax_legomena_to_unique'],
feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)StandardScaler(with_mean=False)
LogisticRegression(max_iter=5000, random_state=55)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)[Pipeline] ...... (step 1 of 4) Processing preprocessor, total= 20.1s
[Pipeline] ......... (step 2 of 4) Processing textstats, total= 0.2s
[Pipeline] ............ (step 3 of 4) Processing scaler, total= 0.0s
[Pipeline] ........ (step 4 of 4) Processing classifier, total= 0.0sprint(classification_report(y_test, y_pred, labels = target_classes, target_names = target_names, digits=3))
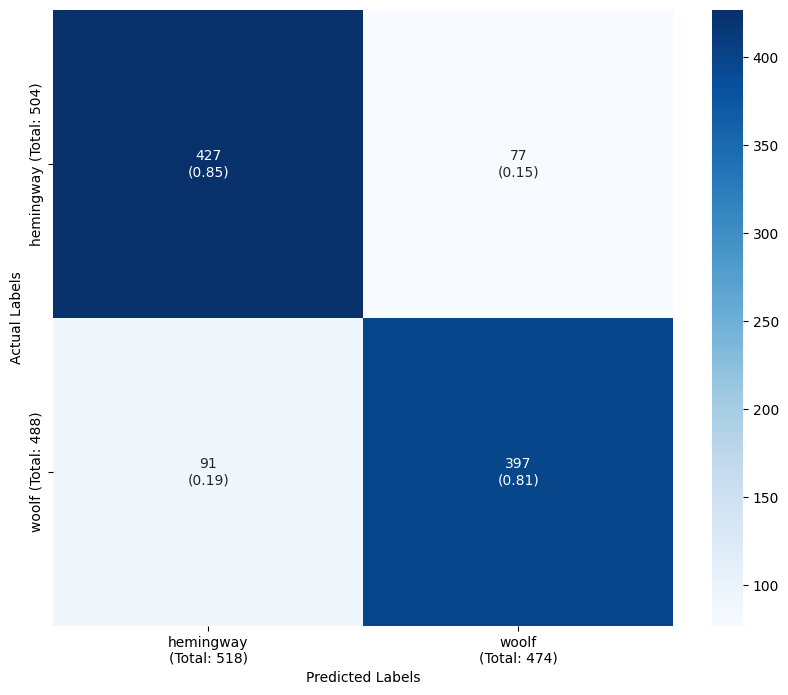
plot_confusion_matrix(y_test, y_pred, target_classes, target_names) precision recall f1-score support
hemingway 0.739 0.782 0.760 504
woolf 0.760 0.715 0.737 488
accuracy 0.749 992
macro avg 0.750 0.748 0.748 992
weighted avg 0.750 0.749 0.749 992
Can we improve on this by selecting features in a data-driven way using recursive feature elimination with cross-validation?
pipeline = Pipeline([
('preprocessor', SpacyPreprocessor(feature_store=feature_store)),
('textstats', TextstatsTransformer(feature_store=feature_store)),
('scaler', StandardScaler(with_mean=False)),
('selector', RFECV(estimator=LogisticRegression(max_iter = 5000, random_state=55), min_features_to_select=4, step=1, cv = 4, verbose=100)),
('classifier', LogisticRegression(max_iter = 5000, random_state=55))
], verbose=True)
display(pipeline)Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('textstats',
TextstatsTransformer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('scaler', StandardScaler(with_mean=False)),
('selector',
RFECV(cv=4,
estimator=LogisticRegression(max_iter=5000,
random_state=55),
min_features_to_select=4, verbose=100)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('textstats',
TextstatsTransformer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)),
('scaler', StandardScaler(with_mean=False)),
('selector',
RFECV(cv=4,
estimator=LogisticRegression(max_iter=5000,
random_state=55),
min_features_to_select=4, verbose=100)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)
TextstatsTransformer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fd8ef0b6e90>)
StandardScaler(with_mean=False)
RFECV(cv=4, estimator=LogisticRegression(max_iter=5000, random_state=55),
min_features_to_select=4, verbose=100)LogisticRegression(max_iter=5000, random_state=55)
LogisticRegression(max_iter=5000, random_state=55)
LogisticRegression(max_iter=5000, random_state=55)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)[Pipeline] ...... (step 1 of 5) Processing preprocessor, total= 0.7s
[Pipeline] ......... (step 2 of 5) Processing textstats, total= 0.2s
[Pipeline] ............ (step 3 of 5) Processing scaler, total= 0.0s
Fitting estimator with 12 features.
Fitting estimator with 11 features.
Fitting estimator with 10 features.
Fitting estimator with 9 features.
Fitting estimator with 8 features.
Fitting estimator with 7 features.
Fitting estimator with 6 features.
Fitting estimator with 5 features.
Fitting estimator with 12 features.
Fitting estimator with 11 features.
Fitting estimator with 10 features.
Fitting estimator with 9 features.
Fitting estimator with 8 features.
Fitting estimator with 7 features.
Fitting estimator with 6 features.
Fitting estimator with 5 features.
Fitting estimator with 12 features.
Fitting estimator with 11 features.
Fitting estimator with 10 features.
Fitting estimator with 9 features.
Fitting estimator with 8 features.
Fitting estimator with 7 features.
Fitting estimator with 6 features.
Fitting estimator with 5 features.
Fitting estimator with 12 features.
Fitting estimator with 11 features.
Fitting estimator with 10 features.
Fitting estimator with 9 features.
Fitting estimator with 8 features.
Fitting estimator with 7 features.
Fitting estimator with 6 features.
Fitting estimator with 5 features.
Fitting estimator with 12 features.
Fitting estimator with 11 features.
Fitting estimator with 10 features.
Fitting estimator with 9 features.
[Pipeline] .......... (step 4 of 5) Processing selector, total= 9.2s
[Pipeline] ........ (step 5 of 5) Processing classifier, total= 0.2sprint(classification_report(y_test, y_pred, labels = target_classes, target_names = target_names, digits=3))
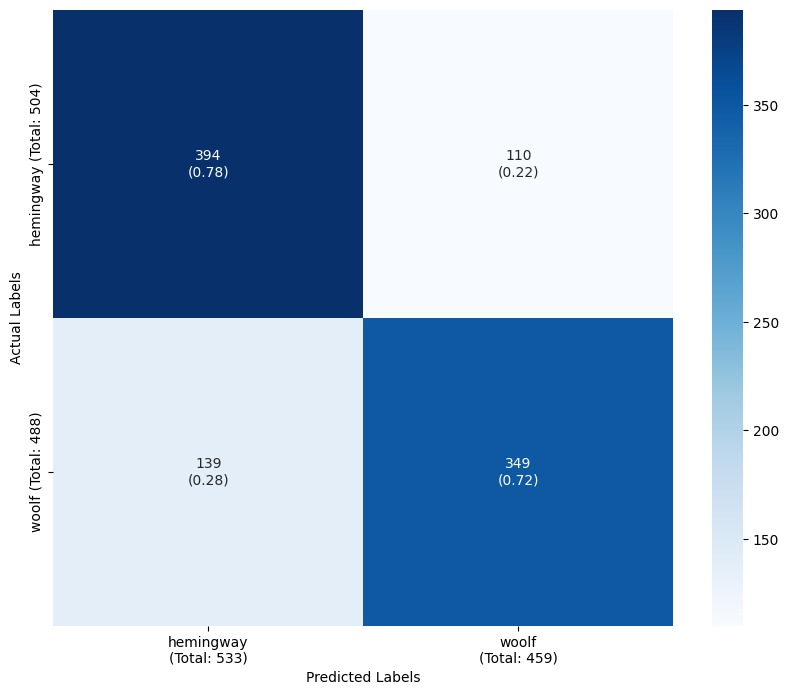
plot_confusion_matrix(y_test, y_pred, target_classes, target_names) precision recall f1-score support
hemingway 0.824 0.847 0.836 504
woolf 0.838 0.814 0.825 488
accuracy 0.831 992
macro avg 0.831 0.830 0.830 992
weighted avg 0.831 0.831 0.831 992