from textplumber.pos import POSVectorizer
from textplumber.preprocess import SpacyPreprocessor
from textplumber.store import TextFeatureStore
from textplumber.core import get_example_data
from textplumber.report import plot_confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler, Normalizer
from sklearn.feature_selection import SelectKBest, mutual_info_classif, chi2pos
Extract parts of speech features.
POSVectorizer
POSVectorizer (feature_store:textplumber.store.TextFeatureStore, ngram_range:tuple=(1, 1), vocabulary:list|None=None)
Sci-kit Learn pipeline component to extract parts of speech tag features. This component should be used after the SpacyPreprocessor component with the same feature store. The component gets the tokens from the feature store and returns a matrix of counts (via CountVectorizer).
| Type | Default | Details | |
|---|---|---|---|
| feature_store | TextFeatureStore | the feature store to use - this should be the same feature store used in the SpacyPreprocessor component | |
| ngram_range | tuple | (1, 1) | the ngram range to use (min_n, max_n) - passed to CountVectorizer |
| vocabulary | list | None | None | list of tokens to use - passed to CountVectorizer |
POSVectorizer.fit
POSVectorizer.fit (X, y=None)
POSVectorizer.transform
POSVectorizer.transform (X)
POSVectorizer.get_feature_names_out
POSVectorizer.get_feature_names_out (input_features=None)
Example
Here is an example demonstrating how to use POSVectorizer.
Here we load text samples from Ernest Hemingway and Virginia Woolf available in the AuthorMix dataset.
X_train, y_train, X_test, y_test, target_classes, target_names = get_example_data(label_column = 'style', target_labels = ['hemingway', 'woolf'])Create a feature store to save preprocessed texts.
feature_store = TextFeatureStore('feature_store_example_pos.sqlite')The SpacyPreprocessor component is required before the POSVectorizer. Here we train a model with Spacy’s simple part-of-speech tags based on the UPOS part-of-speech tag set.
pipeline = Pipeline([
('preprocessor', SpacyPreprocessor(feature_store=feature_store)),
('pos', POSVectorizer(feature_store=feature_store, ngram_range = (1, 1))),
('scaler', StandardScaler(with_mean=False)),
('classifier', LogisticRegression(max_iter = 5000, random_state=55))
], verbose=True)
display(pipeline)Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)
StandardScaler(with_mean=False)
LogisticRegression(max_iter=5000, random_state=55)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)[Pipeline] ...... (step 1 of 4) Processing preprocessor, total= 17.1s
[Pipeline] ............... (step 2 of 4) Processing pos, total= 0.4s
[Pipeline] ............ (step 3 of 4) Processing scaler, total= 0.0s
[Pipeline] ........ (step 4 of 4) Processing classifier, total= 0.0sprint(classification_report(y_test, y_pred, labels = target_classes, target_names = target_names, digits=3))
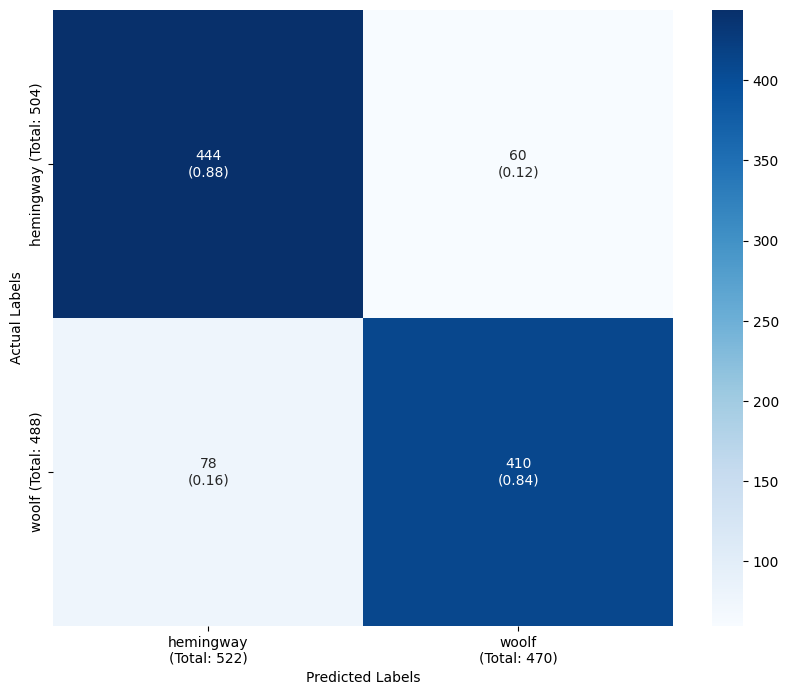
plot_confusion_matrix(y_test, y_pred, target_classes, target_names) precision recall f1-score support
hemingway 0.762 0.831 0.795 504
woolf 0.808 0.732 0.768 488
accuracy 0.782 992
macro avg 0.785 0.781 0.781 992
weighted avg 0.784 0.782 0.782 992
The texts can also be preprocessed using the Spacy’s ‘detailed’ part-of-speech tagset. For the English-language SpaCy models this is based on the Penn Treebank tag set.
In this case we are re-processing the texts, so the feature store needs to be reset to extract part-of-speech tags using the correct tag set. This is likely to be amended in the future to automatically detect if re-processing is needed.
feature_store.empty()pipeline = Pipeline([
('preprocessor', SpacyPreprocessor(feature_store=feature_store, pos_tagset = 'detailed')),
('pos', POSVectorizer(feature_store=feature_store, ngram_range = (1, 1))),
('scaler', StandardScaler(with_mean=False)),
('classifier', LogisticRegression(max_iter = 5000, random_state=55))
], verbose=True)
display(pipeline)Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>)
StandardScaler(with_mean=False)
LogisticRegression(max_iter=5000, random_state=55)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)[Pipeline] ...... (step 1 of 4) Processing preprocessor, total= 18.4s
[Pipeline] ............... (step 2 of 4) Processing pos, total= 0.4s
[Pipeline] ............ (step 3 of 4) Processing scaler, total= 0.0s
[Pipeline] ........ (step 4 of 4) Processing classifier, total= 0.0sprint(classification_report(y_test, y_pred, labels = target_classes, target_names = target_names, digits=3))
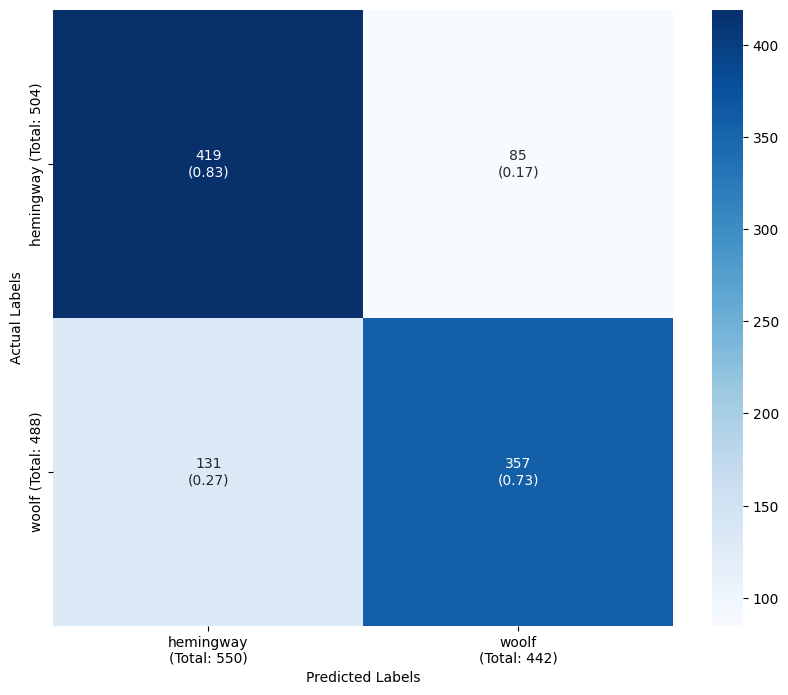
plot_confusion_matrix(y_test, y_pred, target_classes, target_names) precision recall f1-score support
hemingway 0.806 0.909 0.854 504
woolf 0.892 0.775 0.829 488
accuracy 0.843 992
macro avg 0.849 0.842 0.842 992
weighted avg 0.848 0.843 0.842 992
Using the ‘detailed’ tag set improves the classifier’s accuracy.
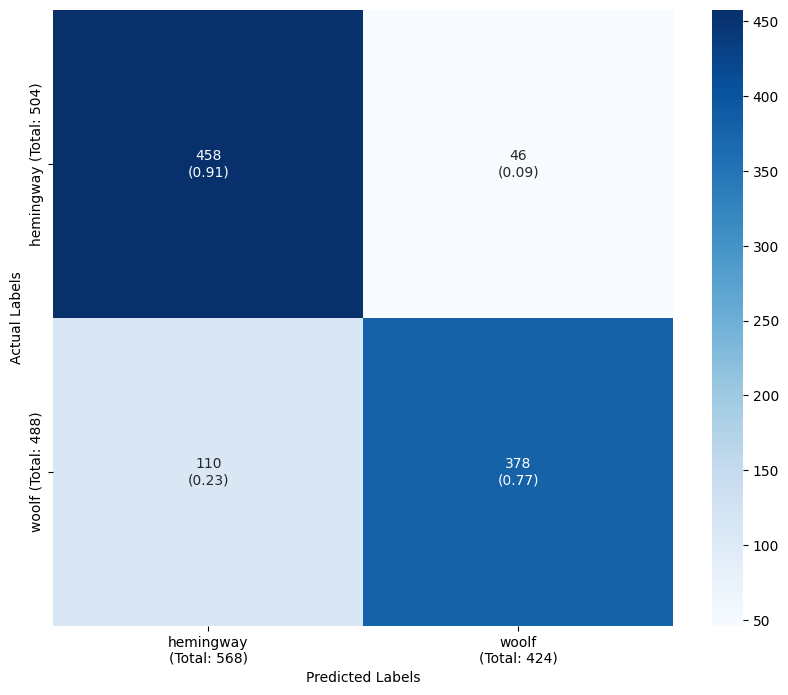
Part-of-speech tag ngrams can also be used as features. In this case we select 200 part-of-speech bigrams. The trained model has boosted accuracy and more balanced performance between classes.
pipeline = Pipeline([
('preprocessor', SpacyPreprocessor(feature_store=feature_store, pos_tagset = 'detailed')),
('pos', POSVectorizer(feature_store=feature_store, ngram_range = (2, 2))),
('selector', SelectKBest(score_func=mutual_info_classif, k=200)),
('scaler', StandardScaler(with_mean=False)),
('classifier', LogisticRegression(max_iter = 5000, random_state=55))
], verbose=True)
display(pipeline)Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
ngram_range=(2, 2))),
('selector',
SelectKBest(k=200,
score_func=<function mutual_info_classif at 0x7fc011c8d440>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')),
('pos',
POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
ngram_range=(2, 2))),
('selector',
SelectKBest(k=200,
score_func=<function mutual_info_classif at 0x7fc011c8d440>)),
('scaler', StandardScaler(with_mean=False)),
('classifier',
LogisticRegression(max_iter=5000, random_state=55))],
verbose=True)SpacyPreprocessor(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
pos_tagset='detailed')POSVectorizer(feature_store=<textplumber.store.TextFeatureStore object at 0x7fc011ca80d0>,
ngram_range=(2, 2))SelectKBest(k=200, score_func=<function mutual_info_classif at 0x7fc011c8d440>)
StandardScaler(with_mean=False)
LogisticRegression(max_iter=5000, random_state=55)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)[Pipeline] ...... (step 1 of 5) Processing preprocessor, total= 0.2s
[Pipeline] ............... (step 2 of 5) Processing pos, total= 0.7s
[Pipeline] .......... (step 3 of 5) Processing selector, total= 2.6s
[Pipeline] ............ (step 4 of 5) Processing scaler, total= 0.0s
[Pipeline] ........ (step 5 of 5) Processing classifier, total= 0.3sprint(classification_report(y_test, y_pred, labels = target_classes, target_names = target_names, digits=3))
plot_confusion_matrix(y_test, y_pred, target_classes, target_names) precision recall f1-score support
hemingway 0.851 0.881 0.865 504
woolf 0.872 0.840 0.856 488
accuracy 0.861 992
macro avg 0.861 0.861 0.861 992
weighted avg 0.861 0.861 0.861 992