This thread highlights postgraduate projects I’ve supervised over the past few years.
Projects I’ve supervised related to the politics of deep-sea mining are discussed in this thread.
An experimental microblog unplugged from social media.
This thread highlights postgraduate projects I’ve supervised over the past few years.
Projects I’ve supervised related to the politics of deep-sea mining are discussed in this thread.
In 2021/2022, as part of my work on the Mapping LAWS project, I supervised a project with Daniel Rance, a student in the Master of Applied Data Science, to build a knowledge graph from texts on autonomous weapons.
Killer Robots Knowledge Graph
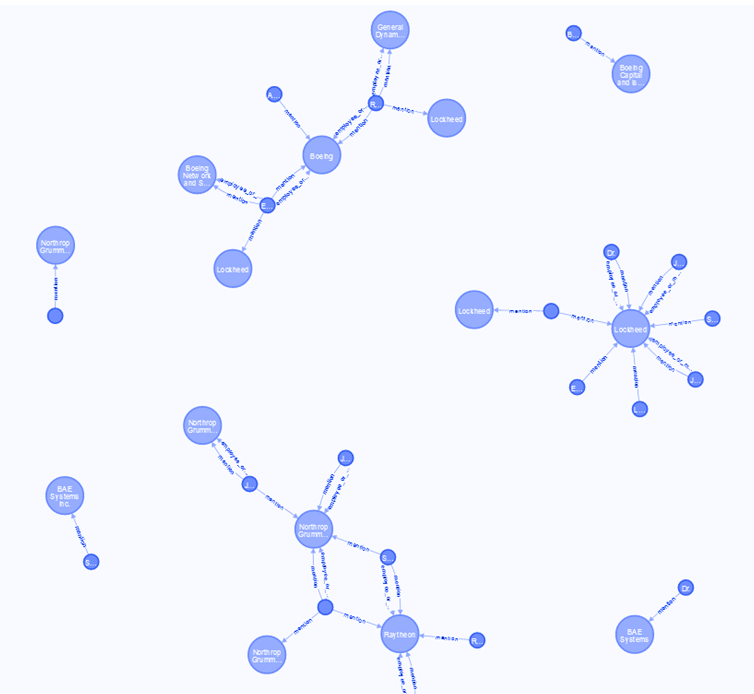
The prospect of banning or regulating lethal autonomous weapon systems (LAWS) has been debated over the last decade. While these debates continue through the United Nations, media and academia, there is ongoing funding and development involving militaries, research institutions and corporations. The Mapping LAWS project is a UC-based research project that is mapping features of discourse and networks related to these emerging weapon systems. The project has built large collections of texts related to these debates from academia, think tanks, militaries, governments, activists, and media and is currently analysing the language of these debates.
The proposed student project with the Mapping LAWS project will build a knowledge graph from our text corpora. We will use the knowledge graph to (1) allow queries based on entities (e.g. querying for what we know about an entity, query to determine similar entities, visualising parts of the knowledge graph) and (2) cluster related entities, including people, organisations, geopolitical entities. The project will involve (1) aligning the results of multiple entity recognition systems (using CoreNLP, Spacy, and a Bert-based model) and gazetteers to reliably extract entities from the corpora; (2) employing pre-trained relation extraction models to connect these entities and populate a knowledge graph; and (3) training a knowledge graph embedding model to allow us to cluster entities and query for similar entities.
The project produced an entity and relation extraction workflow using available pre-trained models. Neo4j was used to store, query, and visualise the graph data.
The workflow was run on a small collection of texts related to people involved in the debate. Neo4J’s Graph Data Science Library was used to train graph embeddings and initial work was undertaken to investigate how these embeddings could be applied in further research.
In 2022/2023 I supervised a group of postgraduate students from the Master of Applied Data Science to work on a project to make use of data from the GeneralIndex.
GeneralIndex Workflow
The GeneralIndex Workflow project aims to create a reproduceable workflow that can be applied to study the contents of a large data-set of academic discourse, namely the GeneralIndex (https://archive.org/details/GeneralIndex). This is a large data-set consisting of the content of millions of journal articles. The content for these articles is not available directly, but keyword and ngram counts are available. The data is available via multiple SQL files intended to populate a PostgreSQL database. These files are large (250GB compressed, approx 10x this extracted).
The project aims to (1) create a tool to query the (smaller, but still large) meta data tables to allow researchers to assess coverage of the GeneralIndex against other databases of scholarly publishing; and (2) develop a workflow to query the ngram/keyword indices for ngrams/keywords to create summary reporting based on metadata (e.g. mentions over time).
The students developed a processing pipeline to wrangle the meta-data files. The students developed and demonstrated a prototype dashboard to allow querying and reporting on the GeneralIndex meta-data. They also scoped out different big data libraries to work with the huge keyword/ngram data-set.
In 2024/2025, I supervised Chanvicheka Korng from the Master of Applied Data Science programme on a project to annotate digitised New Zealand parliamentary debates.
Parse and analyse text data from New Zealand’s parliament
The New Zealand Parliamentary Language Corpus (v2) is a data-set based on a scraped and parsed version of the official online New Zealand Parliamentary Debates (Hansard) spanning the period 2003-2016. There are sub-corpora related to different parties and parliamentary terms. This project will create software tools to (3) scope and create tools to align pre-2003 data sources with the main corpus, and (2) annotate and align the corpus with relevant data sources. This will involve creating text classifiers to aide with segmentation of the data into individual utterances. As part of this project students will report on trends in the data guided using appropriate text analysis methods, with the goal of demonstrating the relevance and value of the data source for political scientists, media and the public.
The project focused on classifying sections of the Hansard records from 1990 to 2002 into headings, speeches and procedural descriptions. A number of rule-based and machine learning models were trained using data from the 2003-2016 data-set consisting of a sample of 10,000 examples of each label type and a variety of feature extraction approaches. These models were evaluated on labelled data from the 1990-2002 data. Random Forest and a Multi-Layer Peceptron models performed best. An ensemble model was also developed that performed better than all individual models (Macro F1: 0.988).
Chanvicheka labelled the 1990-2002 texts using the ensemble and enriched this data with Wikidata on New Zealand Members of Parliament, including their political party affiliation. Experiments with this labelled data indicate that a speaker’s party could be reliably predicted from individual speeches for National and Labour MPs based on TF-IDF scores for word features using a Logistic Regression classifier (F1 score of 0.64). This mirrors results of studies on other legislatures, with misclassifications mostly due to non-policy speeches concerning the procedures of parliament that do not obviously differ by party affiliation.
Thanks for clicking the re-post button. Your interaction will not be shared or recorded and a new random count will generate. The URL has been copied to the clipboard, you can now paste it or share it however you like.
Thanks for the love. Your interaction will not be shared or recorded and a new love count will randomly generate. You should know though, I appreciate the gesture. Right back at you: Favorite
Want to discuss this further? Send me an email mail.