This thread highlights some of my work on a Marsden-funded project on the politics of deep-sea mining in the Pacific, including research I’ve supervised during the project.
An experimental microblog unplugged from social media.
-
-
Since 2024, I’ve supervised three postgraduate research projects related to deep-sea mining. Students from UC’s Master of Applied Data Science programme worked with me to apply LLMs to research on deep sea mining policy texts, developing pipelines for information extraction and retrieval augmented generation.
These supervisions were structured with intensive workshops during the first few weeks of Summer, which involve working alongside students a few hours a day to progress the projects.
-
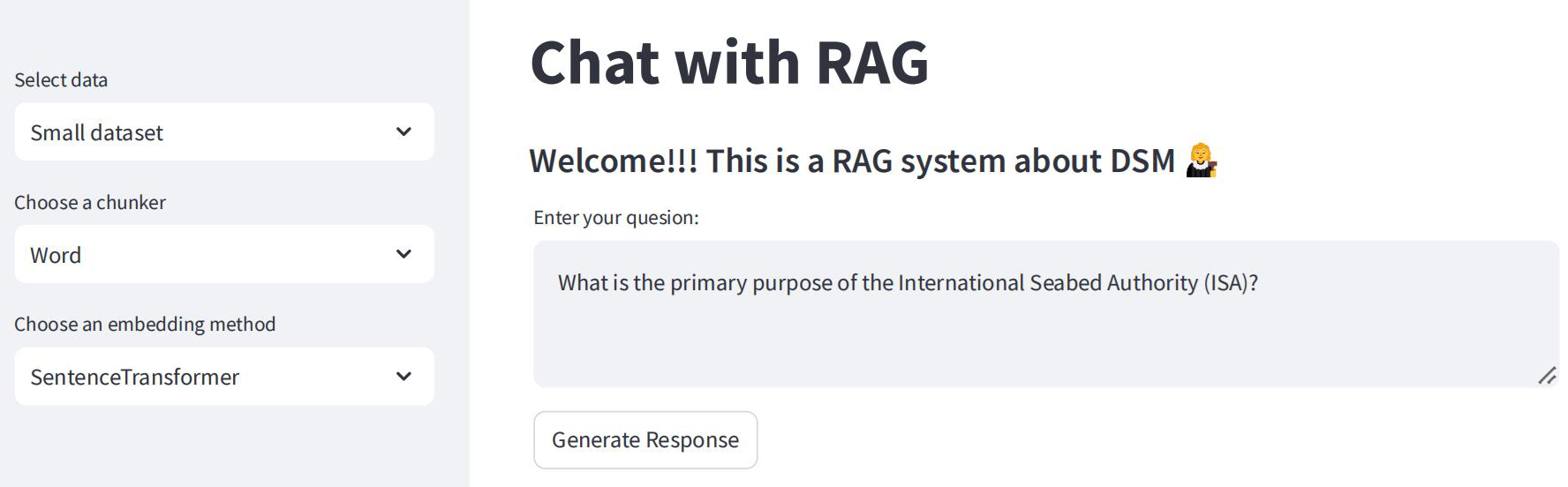
In 2024/2025, I supervised Shan Lu, a student in the Master of Applied Data Science, who developed a prototype Retrieval Augmented Generation (RAG) system to query a corpus of documents on deep-sea mining.
Project title:
Applying Retrieval Augmented Generation (RAG) to Deep-sea Mining Research
Project description:
From Shan Lu’s project report:
This project developed a prototype Retrieval-Augmented Generation (RAG) system intended to allow academic researchers to leverage advanced information retrieval methods and large language models (LLMs) to query and analyse documents related to Deep-Sea Mining (DSM). The document dataset used to develop the RAG-system prototype consisted of 9,249 documents from governments, NGOs, corporations and media. Additional question and answer datasets were generated for evaluating the system. There were three key requirements of the system. Firstly, the intention of this prototype system was to give nontechnical academic researchers a way to query the dataset using natural language and provide visibility of the workings of the RAG system, including the information on which answers are based and evaluation metrics. Secondly, the system needed to allow changing and evaluating different components of the RAG system for accuracy and efficiency, including different text chunking methods, embedding models, vector storage, retrieval methods and large-language models. Thirdly, the intention was to make use of local models where possible to reduce costs, prioritise data security and reduce environmental impacts.
Project Outcomes
Shan produced a prototype system consisting of a software workflow based on LlamaIndex to index the documents and to permit evaluation of the system outputs. She also produced a Streamlit-based dashboard to allow a non-technical user to interact with the system.
Shan compared a variety of chunking approaches, embedding models, vector search algorithms and several small LLMs. In addition, Shan developed a workflow to derive a knowledge graph from the corpus based on co-mentions using GLiNER and allowed the user to query and visualise this via the dashboard.

The project demonstrates the potential of RAG workflows to aide academics working with large text corpora, but also the challenges of working with local LLMs. The project indicates the feasibility of specific chunking and embedding strategies on local machines, including the utility of new approaches to static embeddings like Model2Vec, and the potential to augment RAG with knowledge graphs without the need to use proprietary foundation models for information extraction.
-
During the Summer of 2025-2026, I supervised Meiling Li, a student in the Master of Applied Data Science programme, on a project to develop a novel LLM-based span annotation workflow to aide extraction of structured data from a corpus of policy documents on deep-sea mining.
Project title:
Applying LLMs for span annotation to aide analysis of debates on deep sea mining
Project description:
Classifying spans of tokens according to a defined set of labels is a standard information extraction task. This project examines the utility of LLMs for novel span annotation. One advantage of applying LLMs is that, rather than relying on pre-defined general-purpose label schema, the set of labels can be adapted for the specific research domain. This project will create LLM-based pipelines to annotate spans in texts from a large data-set of documents from governments and NGOs on deep-sea mining. The annotations will include entities, relations, and features of arguments on deep-sea mining (e.g. statements in support of or opposed to deep-sea mining, sources of evidence). The project will compare performance of LLMs of various sizes with established pre-trained information extraction models, as well as the performance of different prompting strategies (zero-shot, one-shot, few-shot, many-shot). The project will do some initial exploratory analysis of the texts, annotated with the best performing model/models, to identify actors advancing and opposing deep-sea mining and key arguments for and against the practice.
Project Outcomes
The project made use of the DSPy framework, which supports a variety of prompting approaches, data-driven prompt optimization strategies, and the potential to leverage limited examples. A small gold-standard data-set of 200 labelled sentences was annotated by Dr Ford using 15 DSM-specific label categories. Meiling produced an LLM-based span annotation pipeline for DSM policy texts and conducted a number of experiments using both local and hosted open weight LLMs.
The project demonstrated that it was possible to achieve strong performance with limited expert-labelled data. The best performing classifier, achieving an exact entity-level Micro-F1 score of 0.713, used GPT-OSS 120B with an expert authored prompt with few-shot examples optimized using DSPy’s BootstrapFewShotWithRandomSearch.
-
During the Summer of 2025-2026, I supervised Lillian Lee from the Master of Applied Data Science programme on a project aiming to mimic how academics in the social sciences undertake document research.
Project title:
Mining documents on Deep-Sea Mining: Augmented retrieval for academic research
Project description:
Standard Retrieval Augmented Generation (RAG) systems aim to retrieve relevant document chunks to provide an LLM with the required context to answer user questions, allowing the LLM to take into account new and relevant information and avoid making things up (i.e. hallucinating). There has been a proliferation of RAG research and RAG variants that aim to improve the likelihood of a high-quality generated answer. There are also alternative approaches that augment retrieval itself, through use of alternative indexes (e.g. based on keyword-based retrieval, LLM-extracted summaries and metadata), LLM-based query rewriting, LLM-based reranking or processing full documents using long context capabilities of new LLMs. Much of the work on RAG is, however, premised on answering straightforward factual questions or accurately summarising information, often from a single “correct” document chunk. Academic research in the social sciences often attempts to answer complex questions through analysis of multiple source documents, critically evaluating the information, analysing different perspectives, and producing an answer that integrates and synthesises the source material, with evidence for each claim in the form of citations. The goal of this project is to create an LLM-powered retrieval workflow to simulate aspects of this process to augment an academic researcher in carrying out document research. This workflow will be applied to a large data-set of policy documents from governments and NGOs, reflecting different stances on deep-sea mining.
Project Outcomes
Lillian compared a standard RAG workflow with a multi-step, agentic retrieval workflow and developed a system to run experiments based on different LLMs.
A key challenge of the project was finding data to evaluate the workflows, especially given the effort required to manually create RAG data for a specific domain and the aim of producing a system that could answer complex questions requiring analysis of information across multiple documents. We developed a novel approach to generate RAG evaluation data premised on automating close-reading and analysis of the texts. After chunking the documents, an LLM agent annotated the chunks using LLM-based argument extraction. From this structured data on DSM arguments, questions were generated that could not be answered from a single document chunk and an answer was generated that made use of the relevant evidence. A judge agent pruned out low-quality question-answer pairs due to inaccuracy, simplicity and other criteria.
Lillian assessed the the retrieval and answer generation of the workflows. The agentic workflow demonstrated better retrieval and higher quality generation across the open weight LLMs tested, with the best results achieved for Qwen3-235B-A22B-Instruct-2507.
-
A huge thanks to Shan, Meiling and Lillian for their excellent work across the projects.
-
My primary work on this project includes software outputs working towards release of a tool for researchers to engage with texts relevant to deep-sea mining, including Textplumber (pipeline components for Sci-kit learn to aide machine learning with text), Conc (a Python library for efficient corpus analysis) and ConText (a browser-based concordancer and text analysis application).
-
I’m currently working on a paper on issues arising from data collection on the project and I’ve recently presented this as a work-in-progress at UC. More on that soon …
Thanks for clicking the re-post button. Your interaction will not be shared or recorded and a new random count will generate. The URL has been copied to the clipboard, you can now paste it or share it however you like.
Thanks for the love. Your interaction will not be shared or recorded and a new love count will randomly generate. You should know though, I appreciate the gesture. Right back at you: Favorite
Want to discuss this further? Send me an email mail.