Why Conc?
Where does Conc come from?
Conc originated in work for my PhD research back to 2013. I had been introduced to corpus linguistics by academics from the Linguistics department at the University of Canterbury. I quickly hit the limits of tools available at the time, which were not designed for large corpora and did not allow extension to develop new analytic approaches. I was doing my PhD after a number of years working as a software developer specialising in web-based applications. As part of my research, I developed a web-based corpus browser to implement analysis of a large corpus of New Zealand’s parliamentary debates. This had a MySQL backend, and combined server-side processing with an interactive web interface. With something built from the ground up, I was able to implement analysis approaches that were most relevant to my research and experiment and extend the techniques used.
Since then, I have applied corpus analysis to research and teaching, and that is where Conc originated and has been developed. In around 2020 I developed a prototype version of Conc based on Numpy. As well as support for Jupyter notebook-based analysis, this was integrated with a web UI for other project team members to use to explore the large corpora we were collecting for the project.
I have recently had the opportunity to take sabbatical leave for research. This has given me the opportunity to release Conc in for other researchers. I hope you find it useful for your research!
Why Conc + Jupyter notebooks for corpus analysis?
Doing corpus analysis using an open source library like Conc and Jupyter notebooks has a number of advantages:
- Notebooks provide a way to record the thinking that happens during the analysis process. Note-taking on analysis undertaken with desktop applications requires jumping between applications, copying output, parameters and other information from the desktop application to your note-taking medium. This is not a restriction of notebooks, because the code, result outputs, and notes can be recorded in one place. Unlike desktop applications, with a notebook you can record what you are doing through your research, what you have found and what you need to do.
- The information stored in a notebook, which reflects the “thinking through analysis” described above, persists. This means you can leave your analysis mid-process in a form that can be easily continued at a later date.
- Notebooks provide a convenient way to share in-progress and completed analysis with other team members. Collaborators can run your code, add their own reporting, and add to the discussion of the results.
- Notebook-based analysis is reproducible analysis. Academic papers don’t typically allow for the detail of analysis to be represented that you’ve probably undertaken. Other researchers can run your code, get the same results, and step through your research process. They can also test your analysis, and change inputs and parameters to test out your analysis.
- Want to do something new? An open source library like Conc allows for interrogation of its inner workings, as well as modification and extension. Conc is built using nbdev, which is a notebook-based software development framework. Code is developed in notebooks, you can download these, inspect the code, and extend the functionality to your own requirements. It is a great platform to develop new approaches to corpus analysis.
Why use Conc?
- Conc supports creation of corpora from different source types.
- Conc handles large corpora.
- Conc is fast!
- Conc outputs tables and visualisations that are clear and interpretable.
- Conc corpus and result formats are documented so you can continue your analysis using your own code, you can develop new techniques and ensure results are presented how you want.
Conc screenshots

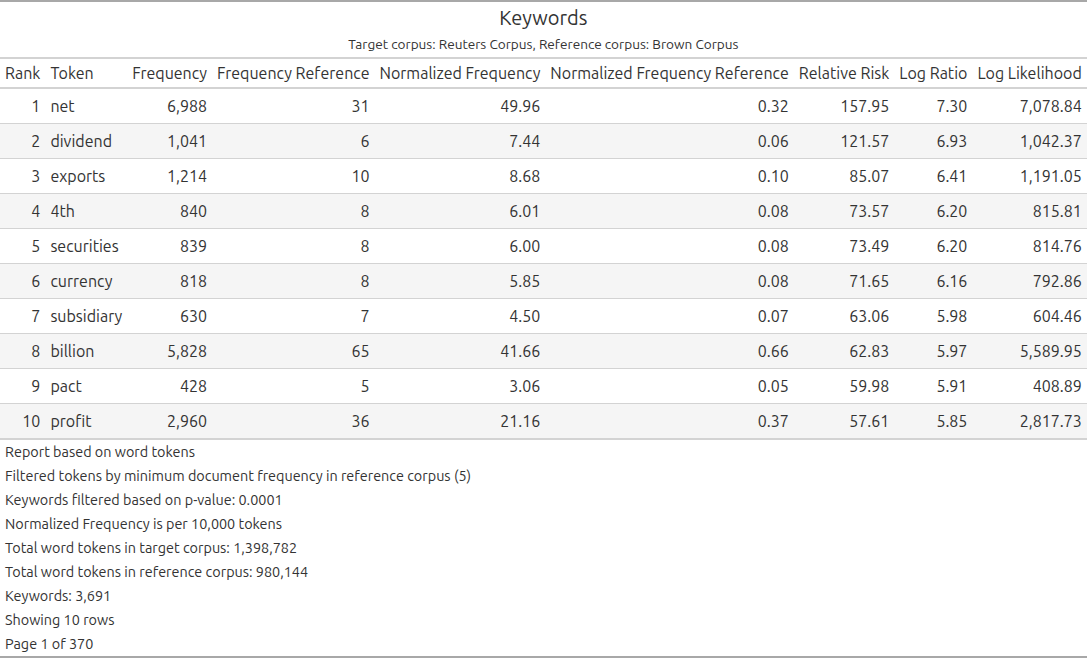
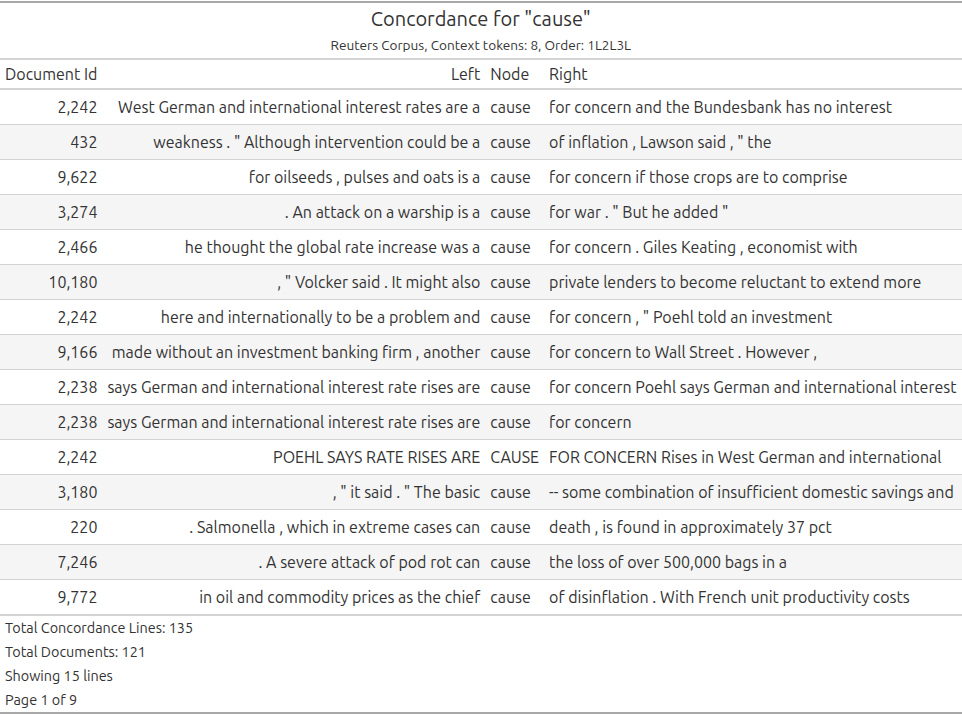
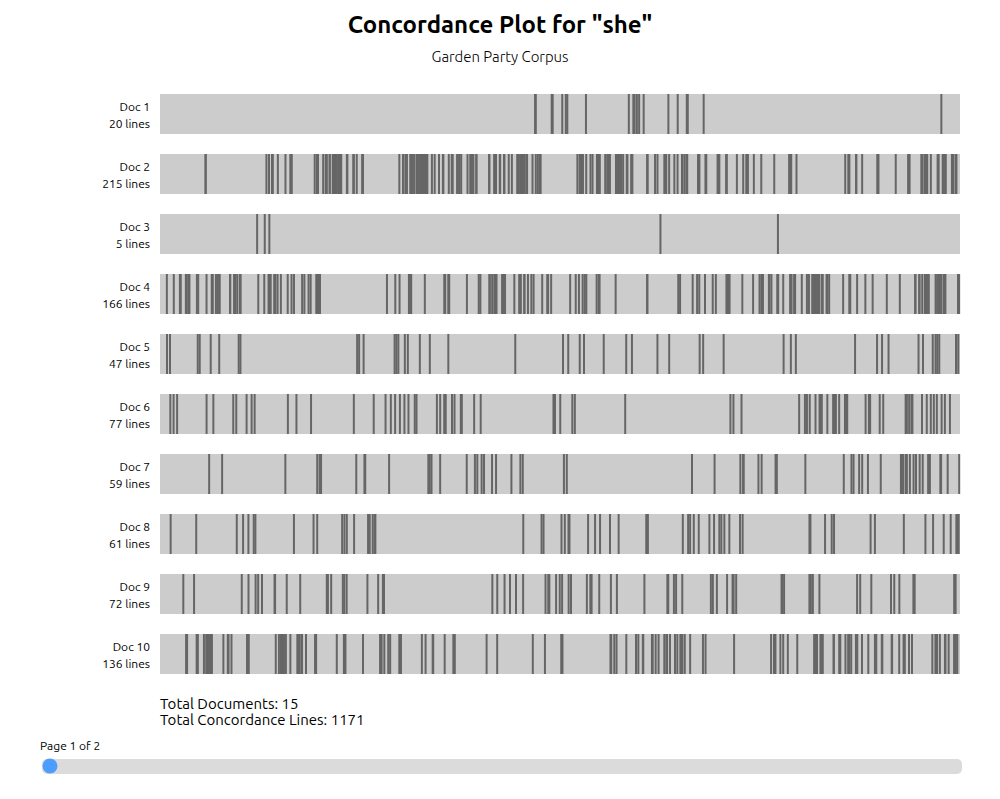
Conc Principles
These principles are intended to guide the development of Conc:
- use standard Python libraries for data processing, analysis and visualisation (i.e. Numpy, Scipy, Polars, Plotly)
- use fast code libraries (i.e. Conc uses Polars vs Pandas) and fast data structures (e.g. Numpy arrays, columnar data stores)
- provide clear and complete information when reporting results
- pre-compute time-intensive and repeatedly used views of the data
- work with smaller slices of the data where possible
- cache specific anaysis during a session to reduce computation for repeated calls
- document corpus representations so that they can be worked with directly
- allow researchers to work with Conc results and extend analysis using other Python libraries (e.g. output Pandas dataframes)
- make use of meta-data to allow within-corpus comparisons and to provide context for analysis